目前facebook已有产品 https://segment-anything.com/demo# 但是总有识别不准的时候,不常见的一些产品,无法识别,这时就需要自已训练模型识别。
使用 PixelLib 进行自定义训练
我们的目标是创建一个可以对蝴蝶和松鼠执行实例分割和对象检测的模型。收集你想要检测的对象的图像并注释数据集以进行自定义训练。Labelme 是用于执行对象的多边形注释的工具。创建根目录或文件夹,并在其中创建训练和测试文件夹。将训练(至少 300 张)和测试所需的图像分开。将要用于训练的图像放在训练文件夹中,并将要用于测试的图像放在测试文件夹中。你将在训练和测试文件夹中对两个图像进行注释。下载Nature 的数据集作为本文中的示例数据集,将其解压缩以提取图像文件夹。该数据集将作为你了解如何组织图像的指南。确保自己的数据集目录的目录格式与它没有不同。Nature 是一个包含蝴蝶和松鼠两个类别的数据集。每个类别有 300 个图像用于训练,每个类别有 100 个图像用于测试,即 600 个图像用于训练,200 个图像用于验证。Nature 是一个包含 800 张图像的数据集。
阅读Medium上的这篇文章,了解如何使用Labelme注释对象。
Nature >>train>>>>>>>>>>>> image1.jpg
image1.json
image2.jpg
image2.json
>>test>>>>>>>>>>>>>>>> img1.jpg
img1.json
img2.jpg
img2.json
注释后的文件夹目录示例。
可视化数据集
在训练之前可视化样本图像,以确认掩模和边界框已正确生成。
import pixellib
from pixellib.custom_train import instance_custom_training
vis_img = instance_custom_training()
vis_img.load_dataset("Nature")
vis_img.visualize_sample()
import pixellib
from pixellib.custom_train import instance_custom_training
vis_img = instance_custom_training()
我们在pixellib中导入,从pixellib导入类instance_custom_training并创建该类的实例。
vis_img.load_dataset("Nature")
我们使用load_dataset 函数加载数据集。PixelLib 要求多边形注释采用 coco 格式,当你调用load_data 函数时,train 和 test 文件夹中的各个 json 文件将分别转换为单个train.json和test.json。训练和测试 json 文件将位于根目录中作为训练和测试文件夹。新的文件夹目录现在如下所示:
Nature >>>>>>>>train>>>>>>>>>>>>>>> image1.jpg
train.json image1.json
image2.jpg
image2.json
>>>>>>>>>>>test>>>>>>>>>>>>>>>>> img1.jpg
test.json img1.json
img2.jpg
img2.json
在 load_dataset 函数内部,注释是从 json 文件中提取的。位图蒙版是根据注释的多边形点生成的,边界框是根据蒙版生成的。封装掩模所有像素的最小框用作边界框。
vis_img.visualize_sample()
当你调用此函数时,它会显示带有蒙版和边界框的示例图像。

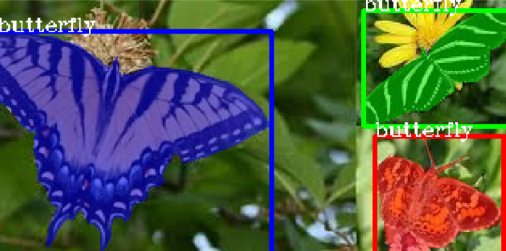
数据集适合训练,load_dataset 函数成功为图像中的每个对象生成掩模和边界框。在 HSV 空间中为蒙版生成随机颜色,然后转换为 RGB。
使用你的数据集训练自定义模型
import pixellib
from pixellib.custom_train import instance_custom_training
train_maskrcnn = instance_custom_training()
train_maskrcnn.modelConfig(network_backbone = "resnet101", num_classes= 2, batch_size = 4)
train_maskrcnn.load_pretrained_model("mask_rcnn_coco.h5")
train_maskrcnn.load_dataset("Nature")
train_maskrcnn.train_model(num_epochs = 300, augmentation=True, path_trained_models = "mask_rcnn_models")
这是执行训练的代码,只需七行代码即可训练数据集。
train_maskrcnn.modelConfig(network_backbone = "resnet101", num_classes= 2, batch_size = 4)
我们将该函数称为modelConfig,即模型的配置。它需要以下参数:
network_backbone:这是 CNN 网络,用作 mask-rcnn 的特征提取器。使用的特征提取器是resnet101。
num_classes: 我们将类的数量设置为数据集中对象的类别。在这种情况下,我们在大自然的数据集中有两个类(蝴蝶和松鼠)。
batch_size:这是训练模型的批量大小。它被设置为 4。
train_maskrcnn.load_pretrained_model("mask_rcnn_coco.h5")
train_maskrcnn.load_dataset("Nature")
我们将采用迁移学习技术来训练模型。Coco模型已经在8O类物体上进行了训练,它学到了很多有助于训练模型的特征。我们调用函数load_pretrained_model函数来加载mask-rcnn coco模型。我们使用load_dataset函数加载数据集。
从这里下载coco模型
train_maskrcnn.train_model(num_epochs = 300, augmentation=True,path_trained_models = "mask_rcnn_models")
最后,我们调用train函数来训练maskrcnn模型。我们调用train_model函数。该函数采用以下参数:
num_epochs:训练模型所需的纪元数。设置为 300。
增强:数据增强应用于数据集,这是因为我们希望模型学习对象的不同表示。
path_trained_models:这是训练时保存训练好的模型的路径。保存验证损失最低的模型。
Using resnet101 as network backbone For Mask R-CNN model
Train 600 images
Validate 200 images
Applying augmentation on dataset
Checkpoint Path: mask_rcnn_models
Selecting layers to train
Epoch 1/200
100/100 - 164s - loss: 2.2184 - rpn_class_loss: 0.0174 - rpn_bbox_loss: 0.8019 - mrcnn_class_loss: 0.1655 - mrcnn_bbox_loss: 0.7274 - mrcnn_mask_loss: 0.5062 - val_loss: 2.5806 - val_rpn_class_loss: 0.0221 - val_rpn_bbox_loss: 1.4358 - val_mrcnn_class_loss: 0.1574 - val_mrcnn_bbox_loss: 0.6080 - val_mrcnn_mask_loss: 0.3572
Epoch 2/200
100/100 - 150s - loss: 1.4641 - rpn_class_loss: 0.0126 - rpn_bbox_loss: 0.5438 - mrcnn_class_loss: 0.1510 - mrcnn_bbox_loss: 0.4177 - mrcnn_mask_loss: 0.3390 - val_loss: 1.2217 - val_rpn_class_loss: 0.0115 - val_rpn_bbox_loss: 0.4896 - val_mrcnn_class_loss: 0.1542 - val_mrcnn_bbox_loss: 0.3111 - val_mrcnn_mask_loss: 0.2554
Epoch 3/200
100/100 - 145s - loss: 1.0980 - rpn_class_loss: 0.0118 - rpn_bbox_loss: 0.4122 - mrcnn_class_loss: 0.1271 - mrcnn_bbox_loss: 0.2860 - mrcnn_mask_loss: 0.2609 - val_loss: 1.0708 - val_rpn_class_loss: 0.0149 - val_rpn_bbox_loss: 0.3645 - val_mrcnn_class_loss: 0.1360 - val_mrcnn_bbox_loss: 0.3059 - val_mrcnn_mask_loss: 0.2493
这是训练日志,它显示了用于训练 mask-rcnn 的网络主干,即resnet101、用于训练的图像数量和用于验证的图像数量。在path_to_trained 模型的目录中,模型是根据验证损失的减少来保存的,典型的模型名称将如下所示:mask_rcnn_model_25–0.55678,它与其纪元号和相应的验证损失一起保存。
Network Backbones:有两个网络主干用于训练 mask-rcnn
1.Resnet101
2.Resnet50
Google Colab: Google Colab 提供单个 12GB NVIDIA Tesla K80 GPU,可连续使用长达 12 小时。
使用Resnet101:训练Mask-RCNN会消耗大量内存。在 google colab 上,使用 resnet101 作为网络主干,你将能够以批量大小 4 进行训练。默认网络主干是 resnet101。Resnet101 被用作默认骨干网,因为它在训练过程中似乎比 resnet50 更快地达到较低的验证损失。它对于具有多个类和更多图像的数据集也更有效。
使用Resnet50:使用resnet50的优点是它消耗更少的内存,你可以在google colab上使用batch_size 6 0r 8,具体取决于colab如何随机分配gpu。支持resnet50的修改后的代码将是这样的。
完整代码
import pixellib
from pixellib.custom_train import instance_custom_training
train_maskrcnn = instance_custom_training()
train_maskrcnn.modelConfig(network_backbone = "resnet50", num_classes= 2, batch_size = 6)
train_maskrcnn.load_pretrained_model("mask_rcnn_coco.h5")
train_maskrcnn.load_dataset("Nature")
train_maskrcnn.train_model(num_epochs = 300, augmentation=True, path_trained_models = "mask_rcnn_models")
与原始代码的主要区别在于,在模型配置函数中,我们将network_backbone设置为resnet50,并将batch size更改为6。
训练日志中唯一的区别是:
Using resnet50 as network backbone For Mask R-CNN model
表明我们正在使用resnet50进行训练。
笔记:给出的batch_sizes是用于google colab的示例。如果你使用的是功能较弱的 GPU,请减小批处理大小,例如具有 4G RAM GPU 的 PC,你应该对 resnet50 或 resnet101 使用批处理大小 1。我使用批量大小 1 在 PC 的 GPU 上训练模型,训练时间少于 100 个 epoch,验证损失为 0.263。这是有利的,因为我的数据集不大。具有更强大 GPU 的 PC,你可以使用批量大小 2。如果你有一个包含更多类和更多图像的大型数据集,请使用 google colab,你可以免费访问可用的单个 12GB NVIDIA Tesla K80 GPU连续12小时。最重要的是,尝试使用更强大的 GPU 并训练更多的 epoch,以生成能够跨多个类别高效执行的自定义模型。通过使用更多图像进行训练来获得更好的结果。建议每类至少 300 张图像作为训练所需的图像。
模型评估
当我们完成训练后,我们应该评估验证损失最低的模型。模型评估用于访问训练模型在测试数据集上的性能。从此处下载经过训练的模型。
import pixellib
from pixellib.custom_train import instance_custom_training
train_maskrcnn = instance_custom_training()
train_maskrcnn.modelConfig(network_backbone = "resnet101", num_classes= 2)
train_maskrcnn.load_dataset("Nature")
train_maskrcnn.evaluate_model("mask_rccn_models/Nature_model_resnet101.h5")
输出
mask_rcnn_models/Nature_model_resnet101.h5 evaluation using iou_threshold 0.5 is 0.890000
模型的 mAP(平均精度)为0.89。
你可以一次评估多个模型,你只需要传入模型的文件夹目录即可。
import pixellib
from pixellib.custom_train import instance_custom_training
train_maskrcnn = instance_custom_training()
train_maskrcnn.modelConfig(network_backbone = "resnet101", num_classes= 2)
train_maskrcnn.load_dataset("Nature")
train_maskrcnn.evaluate_model("mask_rccn_models"
输出日志
mask_rcnn_models\Nature_model_resnet101.h5 evaluation using iou_threshold 0.5 is 0.890000
mask_rcnn_models\mask_rcnn_model_055.h5 evaluation using iou_threshold 0.5 is 0.867500
mask_rcnn_models\mask_rcnn_model_058.h5 evaluation using iou_threshold 0.5 is 0.8507500
import pixellib
from pixellib.custom_train import instance_custom_training
train_maskrcnn = instance_custom_training()
train_maskrcnn.modelConfig(network_backbone = "resnet50", num_classes= 2)
train_maskrcnn.load_dataset("Nature")
train_maskrcnn.evaluate_model("path_to_model path or models's folder directory")
注意:如果你正在评估 resnet50 模型,请将 network_backbone 更改为 resnet50。
访问用于训练自定义数据集的 Google Colab 笔记本设置



