Stable Diffusion 是一种潜在的文本到图像扩散模型,能够在给定任何文本输入的情况下生成照片般逼真的图像,培养自主自由以产生令人难以置信的图像。
https://civitai.com/ 三方流行模型下载
https://huggingface.co/ 机器学习官网,详细文档、模型资源等
https://www.bilibili.com/video/BV1xz4y147xA/ 这里是我演示的一个教程,用于训练文生图demo,有声音的
生成图片的关键在于模型,模型训练是必须掌握的知识,以下是当前几种模型 ,当前版本v0.16.0:
- Unconditional Training 与文本或图像到图像模型不同,无条件图像生成不以任何文本或图像为条件。它仅生成类似于其训练数据分布的图像。
- Text-to-Image Training 文本到图像模型(如稳定扩散)从文本提示生成图像。(用于创作图像)
- Text Inversion 文本反转是一种从少量示例图像中捕获新概念的技术。虽然该技术最初是用潜在扩散模型演示的,但此后已应用于其他模型变体,如稳定扩散。学>习的概念可用于更好地控制从文本到图像管道生成的图像。它在文本编码器的嵌入空间中学习新的“单词”,这些单词在文本提示中用于个性化图像生成。
- Dreambooth 是一种个性化文本到图像模型的方法,例如稳定扩散,只需给定几 (3-5) 张主题图像。它允许模型在不同的场景、姿势和视图中生成主体的上下文>图像。(用于发散)
- LoRA Support 可在消耗更少内存的同时加速大型模型的训练。它将秩分解权重矩阵(称为更新矩阵)对添加到现有权重,并且仅训练那些新添加的权重。(风格训>练)
- ControlNet 将条件控制添加到文本到图像扩散模型
- instructpix2pix 微调文本条件扩散模型的方法,以便它们可以遵循输入图像的编辑指令
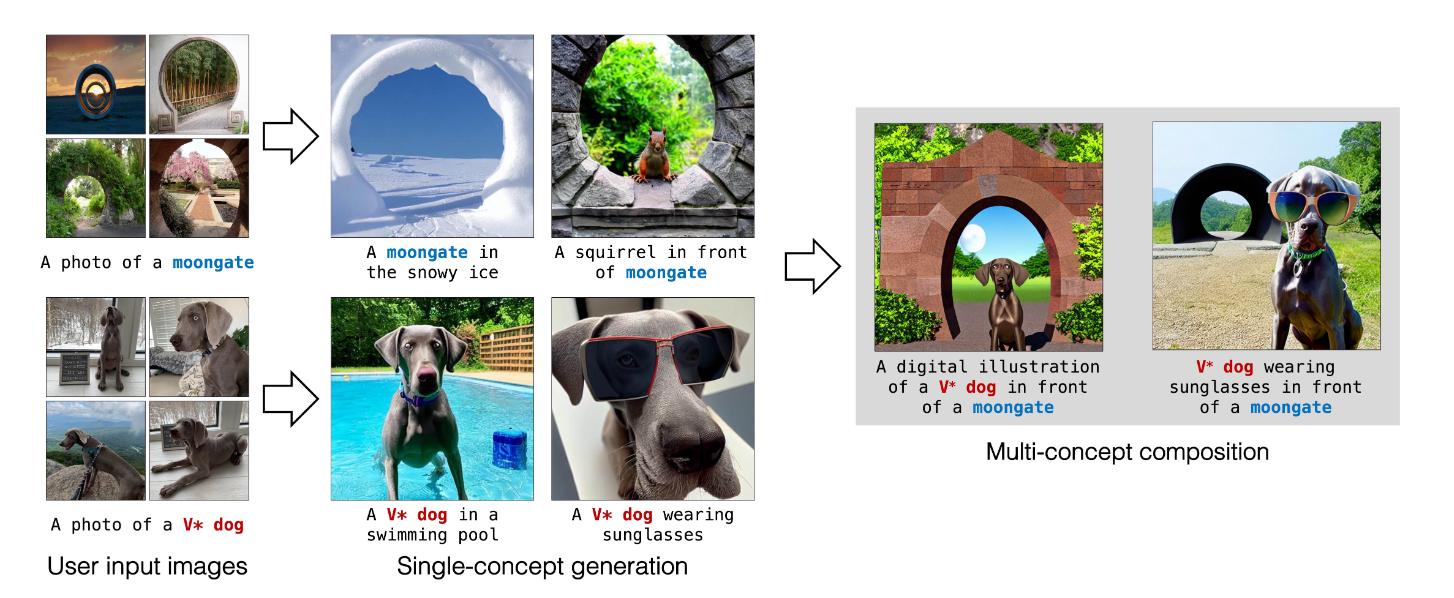
- Custom Diffusion 自定义扩散,比如你指定狗和指定的背景,组合成新的画面。
而我们经常能用到的就是text-to-image, dreambooth, lora 这三种训练算法,其他不需要过多研究,AI生图原理就是对图像进行标注,按着既定规则重新组合。


CLIP原理




