在机器学习中,要改进模型的某些参数,通常需要对其进行衡量。TensorBoard 是用于提供机器学习工作流期间所需测量和呈现的工具。它使能够跟踪实验指标(例如损失和准确率),呈现模型计算图,将嵌入向量投影到较低维度的空间等。
通过命令行 (command) 或在 notebook 体验中启动 TensorBoard ,这两个接口通常是相同的。 在 notebooks, 使用 %tensorboard 命令。 在命令行中, 运行不带“%”的相同命令。
%tensorboard --logdir logs/fit
本快速入门将展示如何快速使用 TensorBoard 。该网站上的其余指南提供了有关特定功能的更多详细信息,此处未包括其中的许多功能。
可以在帖子底部看到我们使用的完整配置,但以下是第一次面部训练中更改的关键内容:
“LR”:3E-06,(基本上是一个我们知道肯定太高的值)
“lr_scheduler”:“线性”,(允许学习率逐渐增加)
“max_epochs”:100,(因为我们的数据只有 20 张图像)
“lr_warmup_steps”:400,(将此数量设置为您将拥有的总步数,详情见下文。这允许线性调度程序上升而不是下降)。
当然,每 1 个 epoch 启用验证,拆分比例为 0.2。
为了直观地了解这里的数字,让我们讨论一些计算。“val_split_proportion”:0.2 表示 20% 的数据将从数据集中分离出来,不会在训练过程中使用,而是用于验证目的。由于我们有 20 张图像,这意味着我们还剩下 16 张图像。
可以将训练过程中的总步数计算为数据集中的图像数量 * max_epoch 和 / batch_size。在本例中为 16*100/4=400。这就是为什么我们将lr_warmup_steps设置为 400,这意味着学习率将从 0 到 3e-06 的设定值,分 400 步,同时线性增加。
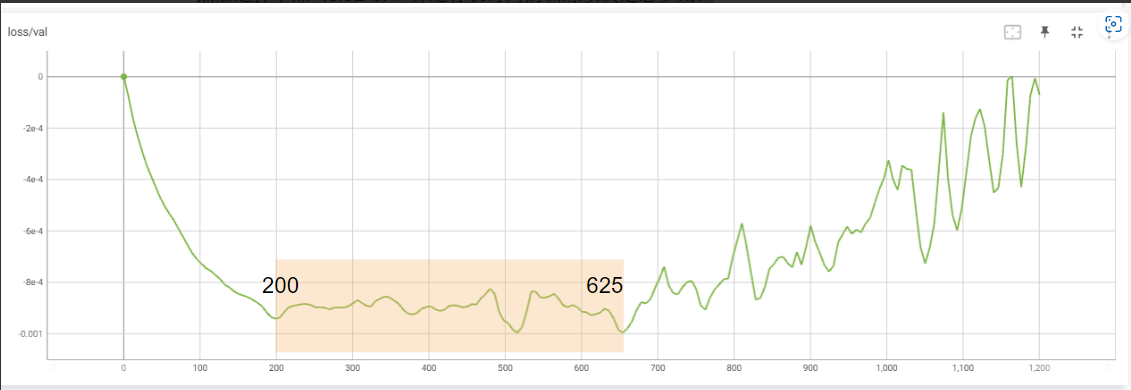
学习率的初步发现 在使用 Damon’s 数据第一次运行后,我们得到了这两个图表:
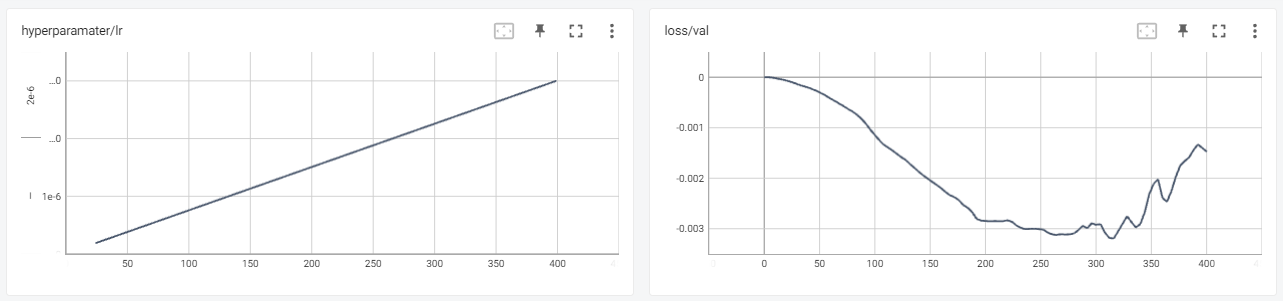
正如预期的那样,学习率在 0 步中以线性方式从 3 增加到 06e-400。在验证损失图上,我们看到预期的行为,模型开始减少损失,然后趋于平缓,最后开始上升。
从理论上讲,我们已经可以从这个图中得出值,但我们决定再做一次运行来放大,因为我们看到在中点,图形已经开始变平然后上升。
所以我们只将“lr”更改为 1.5e-06(即我们将其减少 2 倍,这意味着线性增加将慢 2 倍)并重新运行实验。
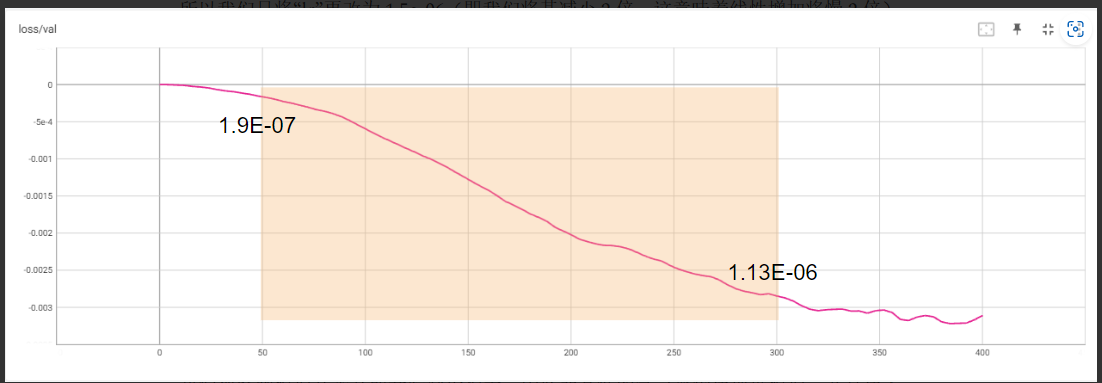
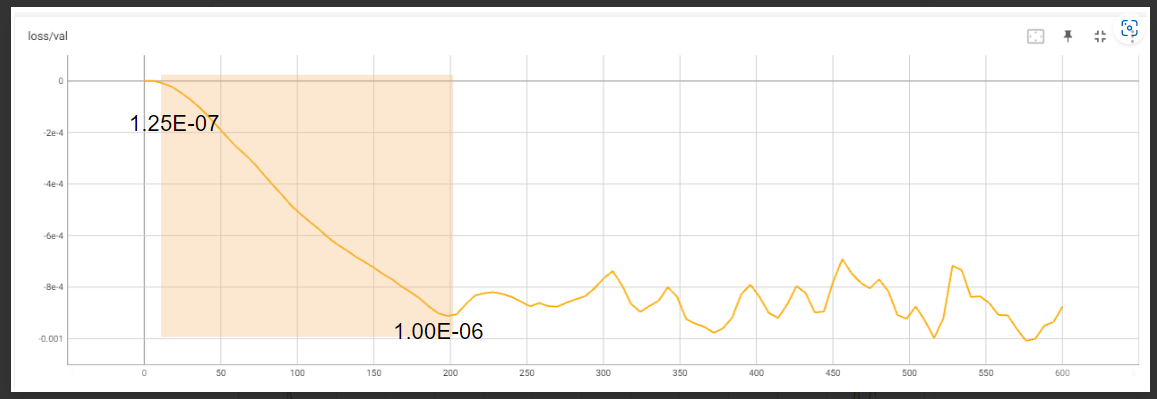
我们观察到模型几乎立即开始减少损失,因此非常低的学习率仍在训练模型,并且在大约 300-350 步时,曲线开始变平。我们决定分别使用下限和上限以及 50 和 300 步,得到下限:1.9E-07 和上限 1.13E-06 的值。
应用研究结果 - 决定步骤数 现在我们有了学习率的范围,我们需要弄清楚如何应用这些发现。在下一篇文章中,我们将讨论一种循环方法,但现在,让我们继续使用线性学习率。为此,我们简单地决定使用计算为 (1.9E-07 + 1.13E-06) / 2 = 6.6E-07 的中点。
获得学习率后的下一个问题是决定训练步骤或纪元的数量。再一次,我们决定使用验证损失读数。这个想法是以发现的 6.6E-07 学习率运行一个模型的时间比通常需要的步骤更长,检查损失图,并查看图变平并开始上升的值。所以我们把lr_scheduler改为常数,max_epochs改为200,当然lr改为6.6E-07。结果,我们得到了下图:
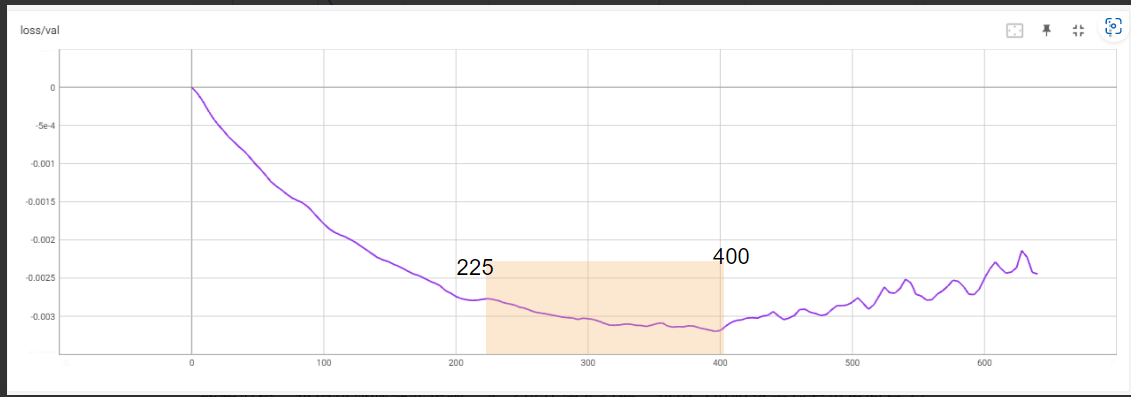
在这种情况下,我们决定应该对总步数 225-400 的某个地方进行最佳训练。可以停在这里,从这个范围内获取检查点并测试输出以确认成功的微调。
但是,鉴于我们有一个额外的小数据集,我们决定更进一步,并在禁用验证的情况下重新进行了训练。请注意,这是一个冒险的步骤,因为我们在没有启用验证的情况下是“盲人”,我们不知道这些添加回来的图像究竟如何影响我们的训练过程。对于足够大的数据集,我们建议跳过此步骤。为了确认这个问题,我们可以将稳定列车损失图与 16 张和所有 20 张图像进行比较,我们看到两者的分歧进一步证实了这种方法的危险。
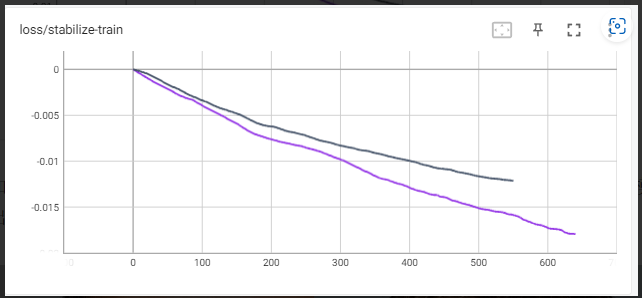
使用风格训练验证查找结果 为了确保这不是随机的侥幸,我们重新运行了整个事情进行风格训练。首先,我们找到了LR范围:
然后选择中点(5.6E-07)并运行长时间的训练以决定总步数: